
Publié le 10 juil. 2025
Partie 1 : Illustration avec le cas des apprenants
Les SI de gestion d’un établissement ESR partagent des objets métiers tels que les personnes, les structures, les nomenclatures, etc. Une bonne intégration de ces SI entre eux implique que ces objets soient en qualité, c’est-à-dire que leur description soit à jour et qu’ils soient identiques en tout point du SI.
Or, une gouvernance des données incomplète ou défaillante peut conduire à la multiplication d’un même objet en différents points du SI voire au sein d’une même application. Dans ce cas, un dédoublonnage est nécessaire afin de mettre le SI en qualité.
Doté de fonctions spécifiques et dédiées au dédoublonnage, un référentiel de données constitue un atout précieux pour améliorer la gouvernance des données de référence en détectant puis en traitant les doublons des objets métier.
Problématique des doublons informatiques sur les apprenants
Dans le cas du domaine de la Formation et Vie de l’Etudiant, l’étudiant, en tant qu’objet métier du SI, évolue au fil du temps. Les données et leurs valeurs caractérisant l’étudiant dans le SI sont modifiées en fonction des changements (on parle de changements d’état de l’objet en lien avec les événements qui déclenchent une action dans le SI).
Ainsi, l’étudiant est vu initialement par le prisme de sa candidature. Son admission, son inscription, son entrée en formation qui va induire des réinscriptions jusqu’à la diplomation sont autant d’événements qui vont faire évoluer les données gérées dans le SI. Au-delà de la diplomation, la relation entre l’établissement et l’étudiant peut se poursuivre. L’étudiant en tant qu’objet du SI peut évoluer est devenir un alumnus, voire devenir un objet métier dans le domaine de la formation continue. C’est pour cela que dans une vision d’apprentissage tout au long de la vie, on parle d’apprenant.
Derrière ces facettes1 d’étudiant, d’alumnus, d’apprenant, il y a une personne physique caractérisée par une identité et un état civil, une domiciliation et globalement des moyens de contact (adresse mail, numéro de téléphone) permettant à l’établissement d’entrer en relation avec cette personne.
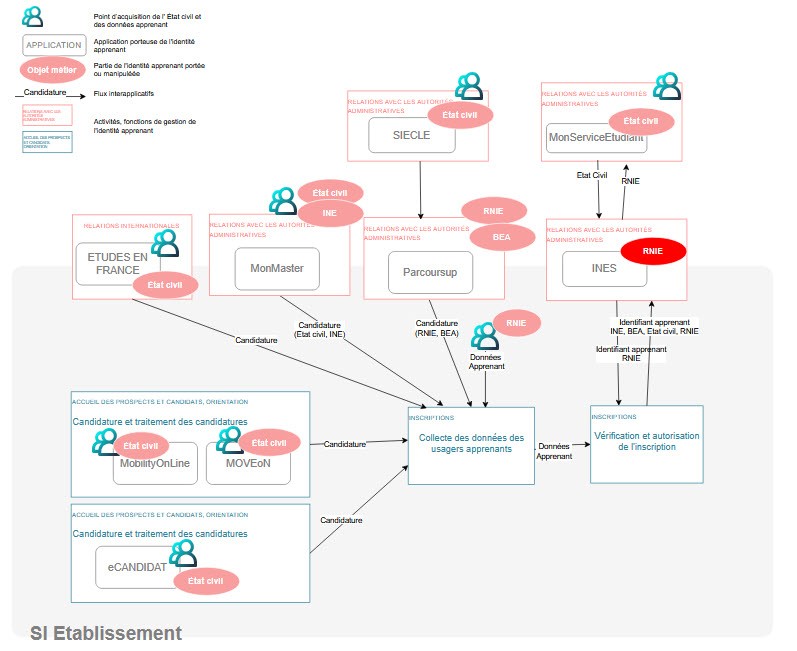
La prise en compte des différents événements qui vont faire évoluer l’objet métier tout au long de ce l’on appelle son cycle de vie se traduit par des interactions humaines avec différents systèmes informatiques ; chaque interaction a pour résultat une modification des données enregistrées, à des moments différents et à des endroits différents (on parle de points d’acquisition).
Ainsi, la multitude des points d’acquisition des données pour un apprenant (cf. figure 1), tout au long du cycle de vie de cet objet, requiert, de la part des systèmes informatiques, une capacité à reconnaître que les différents événements et données associées concernent le même objet ou au contraire des objets différents.
La problématique reste la même depuis que les établissements construisent leurs systèmes d’information et cherchent à en automatiser les processus : comment disposer d’un identifiant unique et pérenne pour un objet métier, en l’occurrence une personne apprenante, permettant d’associer à chaque objet un enregistrement informatique unique qu’il s’agit de mettre à jour au fur et à mesure des changements sur les données (ex : changement d’état civil , d’adresse, inscription administrative, …) ; le but ultime étant d’éviter de créer des doublons informatiques.
Ainsi, l’API INES (Identifiant National dans l’Enseignement Supérieur) permet la vérification et l’immatriculation des étudiants. A partir des données d’état civil, l’API INES détermine s’il existe déjà un enregistrement correspondant dans une base de référence. Dans le cas où les données de l’étudiant correspondent à un enregistrement existant, l’API INES restitue l’identifiant national unique déjà attribué. Dans le cas contraire, elle crée un enregistrement et attribue un nouvel identifiant.
Néanmoins, les données d’état civil ne constituent pas un ensemble de critères suffisamment déterministes pour garantir une vérification certaine à 100%, ne serait-ce que parce que ces données sont saisies au niveau des services en ligne et qu’il n’est pas possible de contrôler leur exactitude à la source. Le cas de figure est d’autant plus important pour les étudiants étrangers.
MonMaster a amplifié cette problématique en permettant aux apprenants de se réimmatriculer quand ils ont oublié l’INE qui leur avait été attribué lors d’une primo inscription.
Le retour d’expérience des établissements montre qu’un volume de doublons informatiques non négligeable est créé dans les SI de gestion. Or la détection de ces doublons est souvent faite quand un problème est remonté par un usager. Il devient alors très difficile de défaire ce qui a été réalisé par les traitements informatiques sur ces doublons pour pouvoir les supprimer. L’ampleur du phénomène a pu être quantifié par les établissements disposant de Sinaps.
Doter son SI d’établissement d’une solution telle que Sinaps
Lorsque Pégase ou Apogée sont connectés à Sinaps afin de lui transmettre les données de l’apprenant ainsi que son inscription administrative, Sinaps vérifie l’existence d’un enregistrement de référence (ou golden record) par rapport aux données transmises. Comme avec l’API INES, le principe de cette vérification est le même : il s’agit de comparer les données disponibles avec celles des enregistrements de référence déjà créés (identifiants, données d’état civil, adresse, etc …).
En revanche, la vérification opérée par Sinaps se base sur trois critères : le score de similitude, le seuil de similitude et le seuil de fusion automatique.
Sinaps calcule un score de similitude entre les données transmises et celles de chaque personne déjà présente dans le référentiel.
Ces scores sont ensuite comparés avec les deux seuils. Si aucun score n’est supérieur ou égal au seuil de similitude, Sinaps considère qu’il s’agit d’un apprenant qui n’est pas encore référencé et Sinaps créé un nouvel enregistrement de référence.
Si un score atteint le seuil de similitude, les données transmises sont considérées comme potentiellement en doublon.
Si le score atteint le seuil de fusion automatique, Sinaps considère, en raison de la similitude très élevée avec l’enregistrement de référence comparé, qu’il s’agit de la même personne. Sinaps fusionne les données avec l’enregistrement de référence.
Donc, la zone grise se situe entre le seuil de similitude et le seuil de fusion. Dans cette zone, Sinaps ne prend pas de décision ; celle-ci doit être prise par un acteur humain.
C’est la différence essentielle entre Sinaps et par exemple l’API INES, ou tout traitement équivalent basé sur un principe de résultat complétement automatique. Un tel traitement ne permet pas d’éviter le risque d’erreur quand il dépend en entrée de données dont la fiabilité n’est pas garantie.
L’association d’un puissant moteur de dédoublonnage et d’une procédure de décision humaine pour les cas suspicieux permet de réduire le risque de doublon de manière drastique.
Le moteur de dédoublonnage de Sinaps

Il permet de répondre à la question : est-ce que la personne dont les données sont présentées à Sinaps dans un flux d’acquisition depuis une application de gestion (ex : Siham pour les personnels salariés et hébergés, Pégase/Apogée pour les apprenants) ou une IHM de Sinaps lui-même (ex : formulaire de saisie d’une personne externe de type « directeur de thèse » ou « membre de jury ») est déjà connue du référentiel ?
Ce moteur est constitué d’un traitement principal qui peut comparer plusieurs attributs ou données constitutives (comme les adresses mail ou postales, …) présentes dans le flux avec les données équivalentes dans le référentiel. Pour chaque enregistrement comparé, un score de similitude (appelé aussi score de rapprochement) est calculé.
En quoi ce traitement constitue-t-il un moteur de dédoublonnage performant ?
Parce qu’il est configurable en fonction des besoins et des contextes. Pour chaque donnée retenue comme critère de comparaison, selon la nature de la donnée (nom, prénom, date de naissance, adresse mail, …), il est possible de choisir l’algorithme de comparaison le plus efficace (Exact, DoubleMetaphone, FuzzySearch, Levenshtein, …).
Le problème avec les algorithmes de comparaison simple basé sur l’égalité stricte de 2 chaînes de caractères est qu’en cas d’erreur de saisie, le résultat de la comparaison est nul. Même en transformant les noms et prénoms en majuscule et en remplaçant les caractères accentués, seul un algorithme de mesure de distance (type Levenshtein) permet de prendre en compte les erreurs. Exemples : Robert Leroy / Robret Leryo ou le fameux Dupont/Dupond.
Avec Sinaps, il est également possible de définir une pondération pour chaque critère et donc de hiérarchiser l’importance des critères (exemple poids fort sur le nom de famille, poids plus faible sur le prénom d’usage et sur la date de naissance, …).
L’ensemble de ces éléments (critères retenus, poids de chaque critère, algorithme de comparaison) constitue une police de rapprochement qu’il est possible de cataloguer et d’utiliser au besoin.
97,18 millions d’opérations !
2,3 secondes (*) avec Sinaps !
97 175 000 est le nombre approximatif d’opérations pour vérifier l’existence d’un apprenant parmi une base de référence de 230 000 personnes (volumétrie UNISTRA en 2023) en faisant une comparaison sur l’INE (exact), le nom de famille (Levenshtein), le prénom usuel (Levenshtein), la date de naissance (Exact), la civilité (Exact) et le pays de naissance (Exact).
Sinaps est optimisé (utilisation d’une technologie moteur de recherche) pour que le temps d’exécution des opérations de comparaison et de calcul de score sur un volume d’enregistrements de référence important soit le plus court possible et peu impacté par l’accroissement de la volumétrie.
(*) Le temps d’acquisition total d’un apprenant est de 5,49 secondes avec 230 000 personnes référencées. L’acquisition comprend deux étapes : le traitement du flux au niveau du bus de service et d’EBX (3,2 secondes indépendamment de la volumétrie) + la vérification de l’existence en faisant le rapprochement avec les enregistrements de référence (2,3 secondes).
Le temps d’acquisition d’une personne-ressource (flux de SIHAM) est de 4,07 secondes pour la même volumétrie.
A suivre, dès la rentrée, la partie 2 : « Illustration avec le cas de la gestion des identités numériques ». Cette seconde partie présentera une cartographie fonctionnelle des échanges de données entre les domaines du SI. Cartographie qui peut constituer une vision cible pour les établissements soucieux de construire une feuille de route d’un projet d’urbanisation autour de la gestion des personnes.
Elle expliquera comment l’Institut pour la Recherche et le Développement (IRD) est parvenu à définir une gouvernance des données autour de Siham, Sinaps et les annuaires techniques pour gérer les flux d’arrivées des personnes : internes ou assimilés, partenaires, sous-traitants, …
Intéressé par Sinaps ?!
Nous vous accueillerons avec plaisir lors du Club'U Sinaps du 6 au 8 octobre
1Dans Sinaps, la notion d’apprenant correspond à un type de rôle. Une personne peut avoir plusieurs rôles, chacun porte des données spécifiques. Ainsi un doctorant qui a un contrat avec l’établissement a deux rôles : un rôle d’apprenant qui porte certaines données de son inscription administrative et un rôle de personne-ressource qui porte certaines données de gestion RH comme son corps, grade, contrat, affectation à une unité organisationnelle qui permet de dériver son responsable hiérarchique, …
Newsletter de l'agence
Les dernières actus de l'Amue dans votre boîte mail ! Inscrivez-vous à notre newsletter.
Besoin d’informations ?
Vous êtes décideur ou correspondant prescripteur au sein d’un établissement ESR et vous souhaitez plus de renseignements sur notre offre de services